들어가며
오늘은 신경망을 중심으로 반복적인 학습을 하는 모델, 딥러닝을 배워보았다. 어떤 상황에 어떤 모델을 사용하는게 최선의 방법일지 오늘 학습내용을 통해 알아보자.
신경망(Neuron Network)
최근에 많은 인기를 끌고 있는 딥러닝(deep learning)의 시작은 1950년대부터 연구되어 온 인공 신경망 (artificial neural network: ANN)이다.
신경망의 장점
- 학습이 가능, 데이터만 주어지면 신경망은 예제로부터 배울 수 있다.
- 몇 개의 소자가 오동작하더라도 전체적으로는 큰 문제가 발생하지 않는다.
퍼셉트론(Perceptron)
퍼셉트론(perceptron)은 1957년에 로젠블라트(Frank Rosenblatt)가 고안한 인공 신경망이다.
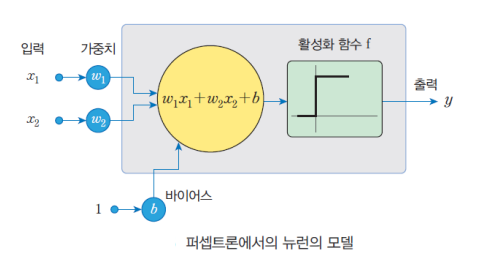
AND와 OR 게이트를 퍼셉트론을 이용해서 예측값을 도출해내는 과정이다. 근데 XOR게이트는 두 값이 다를 때에만 1이 나와야 되는데 모두 0이 나오는 문제가 발생하게된다.
import numpy as np
from sklearn.linear_model import Perceptron
# 샘플과 레이블이다. (AND연산)
X = np.array([[0,0], [0,1], [1,0], [1,1]])
y = np.array([0, 0, 0, 1]) # 활성함수, 계단함수 내장
percetron = Perceptron(tol=0.001, random_state=0)
# tol : 종료조건, 얼마만큼 오차를 허용할 지
percetron.fit(X=X, y=y)
print(percetron.predict(X=X))
# 샘플과 레이블이다. (OR연산)
X = np.array([[0,0], [0,1], [1,0], [1,1]])
y = np.array([0, 1, 1, 1]) # 활성함수, 계단함수 내장
percetron = Perceptron(tol=0.001, random_state=0)
percetron.fit(X=X, y=y)
print(percetron.predict(X=X))
# 샘플과 레이블이다. (XOR연산 : error)
X = np.array([[0,0], [0,1], [1,0], [1,1]])
y = np.array([0, 1, 1, 0]) # 활성함수, 계단함수 내장
percetron = Perceptron(tol=0.001, random_state=0)
percetron.fit(X=X, y=y)
print(percetron.predict(X=X)) # [0 0 0 0] -> [0 1 1 0]
선형 분류 가능 문제
AND나 OR은 하나의 선으로 출력값을 구분할 수 있었다. 근데 XOR같은 경우에는 하나의 선으로 출력값 0과 1을 구분할 수 없다.

이 문제를 해결하기 위해서는 다층퍼셉트론 즉 여러개의 레이어를 사용해야 한다. 아래 그림과 같이 2개의 선형분리로 출력값을 구분해내는 것을 확인할 수 있다.

MLP(Multi Layer Perceptron)
입력층과 출력층 사이에 은닉층(hidden layer)을 가지고 있는 퍼셉트론을 말한다. 은닉층의 개수가 1개인 경우 얕은 신경망이라고 하고, 2개 이상인 경우 깊은 신경망이라고 한다.

활성함수(Activation funtion)
활성화 함수(activation function)은 입력의 총합을 받아서 출력 값을 계산하는 함수이다.
- Sigmoid 함수 : 계단 형식의 함수를 미분이 가능하도록 하는 함수이다. (x = 0인 지점)
- Tangent Hyperbolic 함수 : 확장된 sigmoid함수로서 -1에서 1사이의 출력값을 갖는다.
- ReLU 함수 : 구현이 간단하고 계산적으로 효율적이며 0에서 간단한 임계값 연산으로 정의된다.

활성함수 별 그래프 구현
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x:float) -> float:
return 1.0 / (1.0 + np.exp(-x))
# sigmoid 함수
X = np.arange(-10.0, 10.0, 0.1)
y = sigmoid(x=X)
plt.plot(X,y)
plt.show()

# tangent hyperbolic 함수
x = np.linspace(-np.pi, np.pi, 60)
y = np.tanh(x)
plt.plot(x,y)
plt.show()

# ReLU 함수
def relu(x:float) -> int:
return np.maximum(x, 0) # 0보다 크면, 자기 자신
x = np.arange(-10.0, 10.0, 0.1)
y = relu(x)
plt.plot(x, y)
plt.show()

미니 배치 경사하강법
학습을 할 때 거대한 양을 한꺼번에 학습하는 것이 아닌 일정한 크기만큼 쪼개서 학습을 하는 것을 의미한다. 배치 크기 `batch_size`를 지정하여 랜덤하게 선택한다.
import numpy as np
import tensorflow as tf
# mnist 데이터셋에서 훈련데이터와 테스트데이터 분할
(X_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
print(X_train)
print(y_train)
data_size = X_train.shape[0]
print(data_size) # 60000개
data_size = X_train.shape[0]
batch_size = 12
selected = np.random.choice(data_size, batch_size)
print(selected) # 선택된 값 12개의 인덱스
print(X_train[selected]) # 무작위로 선택된 12개의 데이터
print(y_train[selected]) # 선택된 데이터에 대한 label
XOR 문제를 해결한 신경망 모델
`Dense` 메서드 매개변수
- `units`: 뉴런 개수
- `input_shape`: 입력 데이터의 형태, 입력 값의 개수
- `activation`: 활성 함수의 종류
- `name`: 레이어 이름 지정
import tensorflow as tf
# Sequential모델 : 레이어를 순차적으로 쌓아가는 방식
model = tf.keras.models.Sequential([], name='XOR_MODEL')
# 입력층 생성 Input객체
input_layer = tf.keras.layers.Input(shape=(2,), name='INPUT')
model.add(input_layer)
# 은닉층1 추가
layer1 = tf.keras.layers.Dense(units=4, activation='sigmoid', name='LAYER1')
model.add(layer1)
# 은닉층2 추가
layer2 = tf.keras.layers.Dense(units=2, activation='sigmoid', name='LAYER2')
model.add(layer2)
# 출력층 생성
output_layer = tf.keras.layers.Dense(units=1, activation='sigmoid', name='OUTPUT')
model.add(output_layer)
# 모델 레이어 정보 출력 및 컴파일
model.summary()
model.compile(optimizer=tf.keras.optimizers.SGD(0.7), loss='mse') # mean square 사용
# 모델 학습 후 예측값 출력
X = tf.constant([[0,0], [0,1], [1,0], [1,1]])
y = tf.constant([0, 1, 1, 0])
model.fit(X, y, epochs=10_000)
print(model.predict(X))
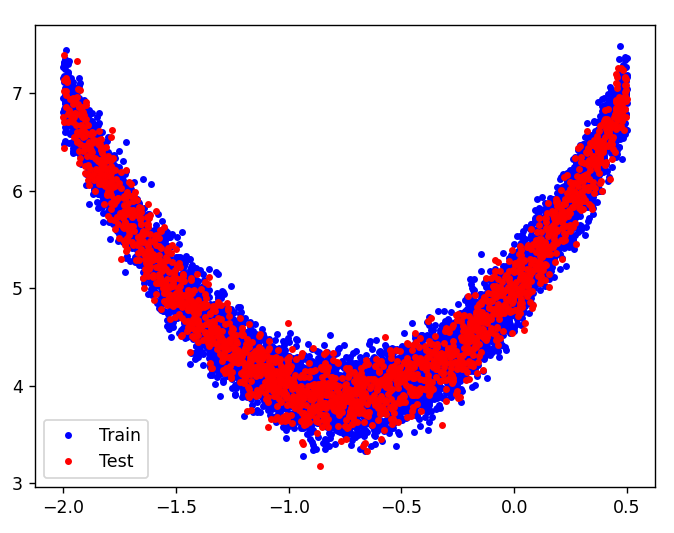
다음은 비선형 모델의 학습과정과 그에 따른 그래프를 나타낸 것이다. 훈련 데이터와 테스트 데이터 모두 비슷한 분포의 2차함수 그래프 형태를 나타내고 있다. 네번째 이미지는 학습의 예측값을 산점도로 나타낸 것인데 오른쪽으로 갈수록 상승하는 모양과 동시에 데이터의 분포도가 낮아지는 것을 확인할 수 있었다.
import numpy as np
import time
from matplotlib import pyplot as plt
SAMPLE_NUMBER = 10_000 # 수 가독성을 위한 언더바_ 표기 C++:10'000
np.random.seed(int(time.time())) # 랜덤시간을 컴퓨터 시간 값으로 시드를 사용
Xs = np.random.uniform(low=-2.0, high=0.5, size=SAMPLE_NUMBER)
np.random.shuffle(Xs)
print(Xs[:15])
ys = 2 * np.square(Xs) + 3 * Xs + 5
plt.plot(Xs, ys, 'r.')
plt.show()
ys += 0.2 * np.random.randn(SAMPLE_NUMBER)
plt.plot(Xs, ys, 'r.')
plt.show()
import tensorflow as tf
# 비선형 모델 생성
model = tf.keras.Sequential(name='NonLinear_MODEL')
# 입력층 생성
input_layer = tf.keras.Input(shape=(1,))
model.add(input_layer)
# 은닉층 3개 생성
model.add(tf.keras.layers.Dense(units=16, activation='relu', name='LAYER1'))
model.add(tf.keras.layers.Dense(units=8, activation='relu', name='LAYER2'))
model.add(tf.keras.layers.Dense(units=4, activation='relu', name='LAYER3'))
# 출력층 생성
model.add(tf.keras.layers.Dense(units=1, activation='relu', name='OUTPUT'))
# 모델 요약 정보 확인 및 컴파일
model.summary()
model.compile(loss='mse', optimizer='adam')
from sklearn.model_selection import train_test_split
# 훈련 데이터 및 테스트 데이터 분할
(X_train, X_test, y_train, y_test) = train_test_split(Xs, ys, test_size=0.2)
# 훈련 데이터 산점도와 테스트 데이터 산점도
plt.plot(X_train, y_train, 'b.', label='Train')
plt.plot(X_test, y_test, 'r.', label='Test')
plt.legend()
plt.show()
# 모델 학습 500번
model.fit(X_train, y_train, epochs=500)
# 학습된 모델의 예측 값 및 산점도
y_predict = model.predict(X_test)
print(y_predict)
print(y_test)
plt.plot(y_predict, y_test, 'r.')
plt.show()


Pima 인디언 당뇨병 데이터셋 활용
Sequential모델을 이용하여 간단한 딥러닝 모델을 구축한 것이다. 그러나 학습과정에서 요약정보에 loss값이 예상과 달리 5~10정도의 너무나 큰 값이 나오는 문제가 발생했다. 출력층에 활성함수를 sigmoid로 사용하면 0.6~7대로 loss값이 많이 낮아졌지만 의도된 값보다는 높았다. 일단 해당 문제를 찾아보고 해결되면 다음 글에 정리해놔야겠다.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 불러오기
df = pd.read_csv(filepath_or_buffer='pima-indians-diabetes3.csv')
print(df.head(10))
print(df['diabetes'].value_counts())
print(df.describe())
# Heat map 그리기(상관관계 확인)
print(df.corr()) # 상관관계 출력
color_map = plt.cm.gist_heat # 컬러맵 지정
plt.figure(figsize=(12,12))
sns.heatmap(df.corr(), linewidths=0.1, vmax=0.5, cmap=color_map, linecolor='white', annot=True)
plt.show()
# keras를 사용한 모델 구성 및 학습
import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input
df = pd.read_csv(filepath_or_buffer='pima-indians-diabetes3.csv')
X = df.iloc[:,:8] # 입력 데이터 첫 8개 열(0~7)
y = df.iloc[:,8] # 정답 데이터 9번째 열(8)
model = Sequential(name='PIMA_INDIANS') # Sequential모델 생성
model.add(Input(shape=(8,))) # 입력층
model.add(Dense(units=16, activation='relu', name='LAYER1')) # 은닉층1 (유닛 16개, ReLU함수)
model.add(Dense(units=8, activation='relu', name='LAYER2')) # 은닉층2 (유닛 8개, ReLU함수)
model.add(Dense(units=4, activation='relu', name='LAYER3')) # 은닉층3 (유닛 4개, ReLU함수)
model.add(Dense(units=1, activation='sigmoid', name='OUTPUT')) # 출력층1 (유닛 1개, sigmoid함수)
model.summary() # 모델 요약정보 출력
# 모델 컴파일 및 학습
model.compile(loss='binary_crossentropy', optimizer=keras.optimizers.Adam(0.1))
model.fit(X, y, epochs=500, batch_size=10) # 학습 500번 배치크기 10
# 학습된 모델로 예측값 생성
y_predict = model.predict(X)
print(y_predict)
print(y)
# 예측값과 실제값 그래프
plt.plot(y_predict, y)
plt.show()마무리
은닉층을 여러개 쓰는 딥러닝을 간단하게나마 구현해보았는데 어떠한 모델을 사용하는 것이 적합한지 아직은 잘 와닿지 않는다. 또한 위에서 언급했던 것처럼 딥러닝 학습과정에서 오차율이 매우 크게 나왔기 때문에 관련된 사례를 많이 찾아보고 알맞게 적용할 수 있도록 해야겠다.
'ABC부트캠프 테크노트' 카테고리의 다른 글
| [24일차] ABC부트캠프 : 딥러닝3 (0) | 2024.08.06 |
|---|---|
| [23일차] ABC부트캠프 : 딥러닝2 (0) | 2024.08.06 |
| [21일차] ABC부트캠프 : ESG포럼 & 세미나3 (0) | 2024.08.02 |
| [20일차] ABC부트캠프 : 머신러닝2 (0) | 2024.07.31 |
| [19일차] ABC부트캠프 : 머신러닝1 (0) | 2024.07.30 |