들어가며
어제 당뇨병 데이터를 활용하다가 끝났기 때문에 그래프로 시각화하는 부분부터 마저 이어서 진행해보자.
당뇨병 데이터셋
선형회귀를 이용해서 모델을 학습시킨 후 그래프를 그려보았다. 모델 성능 수치는 `0.3554944130715042`로 낮게 나왔다. 그래프를 봐도 테스트 데이터가 예측모델에 근접하다고 말하기는 어려울 것 같다.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 당뇨병 데이터 가져오기
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
print(diabetes_X)
print(diabetes_X.shape)
print(diabetes_y)
print(diabetes_y.shape)
# bmi만 추려내서 2차원 배열로 만들기. bmi 특징의 인덱스가 2이다.
bmi = diabetes_X[:, np.newaxis, 2] # 축 생성
print(bmi)
print(bmi.shape)
# 학습용 데이터와 테스트용 데이터 분할
(X_train, X_test, y_train, y_test) = train_test_split(bmi, diabetes_y, test_size=0.2)
print(X_train)
print(X_train.shape)
print(X_test)
print(X_test.shape)
regression = LinearRegression() # 클래스 : 생성자 호출
regression.fit(X_train, y_train)
# 테스트
y_predicts = regression.predict(X_test)
print(y_predicts)
print(y_test)
print(regression.score(X_train, y_train))
# 그래프 그리기
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, y_predicts, color='blue', linewidth=3)
plt.show()

K-NN : 붓꽃 데이터셋 활용
저번 시간에 선형회귀를 이용해서 붓꽃의 종류를 예측해보았다. 이번에는 knn알고리즘을 이용하여 붓꽃의 종류를 예측해보자. knn은 K-Nearest Neighbor의 약자로 어떤 데이터가 주어지면 그 주변(이웃)의 데이터를 살펴본 뒤 더 많은 데이터가 포함되어 있는 범주로 분류하는 방식이다. 예시로 k=4일 때 즉, 주어진 데이터 주변에 4개의 학습데이터가 존재한다고 가정해보자. 이 범위 내에서는 빨간색이 파란색보다 거리가 더 가까우므로, 주어진 데이터를 빨간색인 클래스2로 분류를 하게된다. knn은 알고리즘이 매우 단순하고 직관적이며, 사전학습이나 특별한 준비 시간이 필요 없다는 장점이 있다. 반면에 데이터 인스턴스, 클래스, 특징의 요소들의 개수가 많아진다면 그만큼 많은 메모리 공간과 계산시간이 증가한다는 단점 또한 존재한다.

이제 knn알고리즘을 이용하여 붓꽃데이터를 학습시켜보자. 여기서는 k값을 5로 설정해줬다. k값은 홀수로 지정해주는 게 좋은데 그 이유는 짝수로 지정하면 동점상황 발생 시 하나의 결과를 도출할 수 없기 때문이다. 학습을 시킨 후 `score()`와 `accuracy_score()`를 이용해서 성능을 계산하는데 두 메서드의 차이가 무엇인지 궁금해서 찾아봤다.
| `accuracy_score` | * 주로 분류 모델에서 사용되며, 정확도를 측정 * 모델의 예측값이 필요 |
| `score` | * 주로 회귀 모델에서 사용되며, 결정 계수 (R² 점수)를 측정 * 모델 객체에 따라 다른 수치를 반환 |
붓꽃을 알맞은 종류에 맞게 분류하기 위함이므로 `accuracy_score`가 더 적합할지도 모르겠다. 코드를 실행해보면 30개의 데이터 중 28개가 일치하는 것을 확인할 수 있다. (`28/30 == 0.93333..`) 또한 새로운 붓꽃 데이터를 임의로 생성한 후 그 데이터가 어떤 붓꽃으로 분류하는지 확인하면 `SETOSA`로 분류한 것을 확인할 수 있었다.
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn import metrics
# 붓꽃 데이터셋 가져오기
iris = load_iris()
print(iris)
print(iris.data)
print(iris.target)
# 붓꽃 데이터 셋의 특징이름을 열로 지정하여 데이터프레임으로 변환
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
# target열을 새로 만들고 붓꽃의 target시리즈를 추가
iris_df['target'] = pd.Series(iris.target)
print(iris_df)
print(iris_df.head())
print(iris_df['target'].value_counts())
# 학습데이터, 훈련데이터 분할
(X_train, X_test, y_train, y_test) = train_test_split(iris.data, iris.target, test_size=0.2)
print(X_train)
print(X_train.shape)
# k값이 작을수록 학습에 최적화가 잘됨 k=3일 때 96%(과대적합)
# 3보다는 5,7이 나음 / k값은 홀수가 좋음 / 5가 좋다
k = 5
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
y_predicts = knn.predict(X_test)
print(knn.score(X_train, y_train))
print(y_predicts)
print(y_test)
print()
score = metrics.accuracy_score(y_test, y_predicts)
print(score)
classes = {0:'SETOSA', 1:'VERSICOLOR', 2:'VIRGINICA'}
found_new_iris = np.array([[4.0, 2.0, 1.3, 0.4]])
index = knn.predict(found_new_iris)
print(knn.predict(found_new_iris))
print(classes[index[0]])
[참고] 과잉적합 vs 과소적합
- 과잉 적합(overfittng)이란 학습하는 데이터에서는 성능이 뛰어나지만 새로운 데이터(일반화)에 대해서는 성능이 잘 나오지 않는 모델을 생성하는 것이다.
- 과소적합(underfitting)이란 학습 데이터에서도 성능이 좋지 않은 경우이다.
과소 적합 같은 경우 모델 자체가 적합하지 않은 경우가 많기 때문에 더 나은 모델을 찾아야한다.

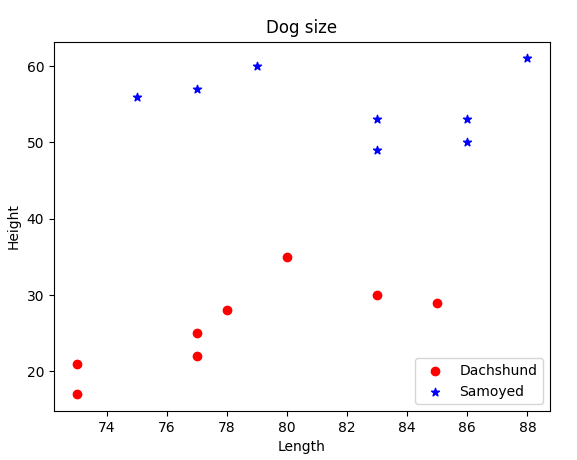
닥스훈트와 사모예드 데이터 활용
닥스훈트와 사모예드의 높이, 길이 데이터를 바탕으로 어떤 종에 해당하는지 분류해볼 수 있다. 닥스훈트는 상대적으로 길이가 길고 높이가 낮은 반면, 사모예드는 길이는 비슷하지만 높이가 더 높은 것을 알 수 있다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
# 닥스훈트 길이, 높이 데이터
dachs_length = [77, 78, 85, 83, 73, 77, 73, 80]
dachs_height = [25, 28, 29, 30, 21, 22, 17, 35]
# 사모예드 길이, 높이 데이터
samo_length = [75, 77, 86, 86, 79, 83, 83, 88]
samo_height = [56, 57, 50, 53, 60, 53, 49, 61]
# 닥스훈트, 사모예드의 산점도
plt.scatter(dachs_length, dachs_height, c='red',
marker='o', label='Dachshund')
plt.scatter(samo_length, samo_height, c='blue',
marker='*', label='Samoyed')
plt.xlabel('Length')
plt.ylabel('Height')
plt.title('Dog size')
plt.legend(loc='lower right') # 범례
plt.show()
새로운 개의 데이터를 임의로 생성하여 이전 그래프와 함께 겹쳐서 확인해본다. 얼핏 보면 닥스훈트에 가까워보이는 모습이다.
# 새로운 개의 데이터
new_dog_length = [79]
new_dog_height = [35]
# 새로운 개가 어디에 근접한지 확인
plt.scatter(new_dog_length, new_dog_height,
marker='p', c='cyan', label='new dog')
plt.show()
이제 닥스훈트의 데이터와 사모예드의 데이터를 바탕으로 새로운 개의 데이터가 어디에 속하는 지 확인하는 과정을 거쳐보자. 닥스훈트를 0, 사모예드를 1로 두고 knn알고리즘을 이용하여 k값을 5로 설정한다. 새로운 개의 데이터(길이:75, 높이:35)를 `predict`메서드의 매개변수로 지정하여 결과를 확인해보면 닥스훈트로 분류한 것을 확인할 수 있다.
# 닥스훈트 데이터 | column_stack : 1차원 배열들을 컬럼으로 쌓아 2차원 배열로 만들기
dachs_data = np.column_stack((dachs_length, dachs_height))
print(dachs_data)
print(dachs_data.shape)
dachs_label = np.array([0, 0, 0, 0, 0, 0, 0, 0,])
print(dachs_label)
print(dachs_label.shape)
# 사모예드 데이터
samoyed_data = np.column_stack((samo_length, samo_height))
print(samoyed_data)
print(samoyed_data.shape)
samoyed_data_label = np.ones(len(samoyed_data))
print(samoyed_data_label)
print(samoyed_data_label.shape)
# 새로운 개 데이터 길이 75cm, 높이 35cm
new_dog_data = np.array([[75, 35]])
print(new_dog_data)
print(new_dog_data.shape)
# 닥스, 사모예드 데이터를 행방향으로 결합
dogs_data = np.concatenate((dachs_data, samoyed_data), axis=0)
print(dogs_data)
print(dogs_data.shape)
# 닥스, 사모예드의 예측 대상 항목을 열방향으로 결합
dogs_label = np.concatenate((dachs_label, samoyed_data_label))
print(dogs_label)
print(dogs_label.shape)
# 가장 근접한 k개의 데이터들을 바탕으로 예측 성능
k = 5
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(dogs_data, dogs_label)
print(knn.score(X=dogs_data, y=dogs_label))
y_predicts = knn.predict((dogs_data))
print(dogs_label)
# 새로운 개를 입력으로 넣었을 때의 새로운 예측 데이터
predict_new_dog = knn.predict(X=new_dog_data)
print(predict_new_dog)
# 새로운 개의 예측 분류
classes = {0:'Dachshund', 1:'Samoyed'}
print(f'새로운 강아지는 : {classes[predict_new_dog[0]]}로 예측된다.')
번외로 데이터의 개수를 늘려 정확도를 늘릴 수도 있다. 닥스훈트 200개, 사모예드 200개 총 400개의 데이터를 평균값을 기반으로 생성해주고, knn알고리즘을 적용한 훈련정확도와 테스트 정확도를 계산해보았다. 각각 0.971875, 0.9625등 높은 성능을 보여주었다.
# 통계적 기반으로 데이터 증강해보기
# 닥스훈트
dachs_length_mean = np.mean(dachs_length)
dachs_height_mean = np.mean(dachs_height)
print(f'닥스훈트 길이의 평균 : {dachs_length_mean}\tcm')
print(f'닥스훈트 높이의 평균 : {dachs_height_mean}\tcm')
new_normal_dachs_length = np.random.normal(dachs_length_mean, 8.0, 200)
new_normal_dachs_height = np.random.normal(dachs_height_mean, 8.0, 200)
print(new_normal_dachs_length)
print(new_normal_dachs_length.shape)
print(new_normal_dachs_height)
print(new_normal_dachs_height.shape)
# 사모예드
samo_length_mean = np.mean(samo_length)
samo_height_mean = np.mean(samo_height)
print(f'사모예드 길이의 평균 : {samo_length_mean}\tcm')
print(f'사모예드 높이의 평균 : {samo_height_mean}\tcm')
new_normal_samo_length = np.random.normal(samo_length_mean, 8.0, 200)
new_normal_samo_height = np.random.normal(samo_height_mean, 8.0, 200)
print(new_normal_samo_length)
print(new_normal_samo_length.shape)
print(new_normal_samo_height)
print(new_normal_samo_height.shape)
plt.scatter(new_normal_dachs_length, new_normal_dachs_height, c='b', marker='+')
plt.scatter(new_normal_samo_length, new_normal_samo_height, c='r', marker='*')
plt.show()
# 새로운 데이터 합성하기
new_dachs_data = np.column_stack((new_normal_dachs_length, new_normal_dachs_height))
new_samo_data = np.column_stack((new_normal_samo_length, new_normal_samo_height))
# 새로운 레이블 합성하기
new_dachs_label = np.zeros(len(new_dachs_data)) # 200
new_samo_label = np.ones(len(new_samo_data)) # 200
print(new_dachs_data)
print(new_dachs_data.shape)
print(new_samo_data)
print(new_samo_data.shape)
print(new_dachs_label)
print(new_samo_label)
# 총 400개의 개 데이터 만들기
new_dogs = np.concatenate((new_dachs_data, new_samo_data))
new_labels = np.concatenate((new_dachs_label, new_samo_label))
print(new_dogs.shape)
print(new_labels.shape)
# 훈련데이터 + 테스트데이터 분리하기
(X_train, X_test, y_train, y_test) = train_test_split(new_dogs, new_labels, test_size=0.2)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
k = 7
knn = KNeighborsClassifier(k)
knn.fit(X=X_train, y=y_train)
print(f'훈련 정확도 : {knn.score(X_train, y_train)}')
# 예측하기
y_predicts2 = knn.predict(X_test)
print(y_predicts2)
print(y_test)
print(f'테스트 정확도 : {accuracy_score(y_test, y_predicts2)}')
plt.plot(y_predicts2, y_test, 'b')
plt.show()
MNIST 필기체 숫자 분류
sklearn을 사용하여 필기체 숫자 이미지를 인식하는 프로그램을 작성해보자.

8 * 8 크기의 행렬형태로, 흰색인 배경은 0이고 필기된 부분은 일정한 값이 들어있는 형태이다. 테스트 데이터인 `X_test`의 인덱스가 0인 값은 6이었는데 이 값을 입력데이터로 넣었을 때의 예측 결과가 6으로 일치하는 것까지 확인할 수 있었다.
from sklearn import datasets, metrics
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import numpy as np
# 필기체 데이터 불러오기
digits = datasets.load_digits()
print(digits)
print(digits.images[0])
print(digits.data[0].shape)
plt.imshow(digits.images[2], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
plt.imshow(digits.data[0].reshape(8,8), cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
# n_samples = len(digits.images)
# print(n_samples)
# data = digits.images.reshape((1791, -1))
(X_train, X_test, y_train, y_test) = train_test_split(np.array(digits.data),
digits.target, test_size=0.3,
random_state=42)
k = 5
knn = KNeighborsClassifier(k)
knn.fit(X_train, y_train)
print(knn.score(X_train, y_train))
y_predictions = knn.predict(X_test)
print(y_predictions)
print(y_test)
print(metrics.accuracy_score(y_test, y_predictions))
print(y_test[0])
plt.imshow(X_test[0].reshape(8, 8), cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
y_predict = knn.predict([X_test[0]])
print(y_predict)
print(y_test[0])



선형 회귀 실습 - 키와 몸무게에 따른 예측값
- 인간의 키와 몸무게는 어느 정도 비례할 것으로 예상된다. 아래와 같은 데이터가 있을 때, 선형 회귀를 이용하여 학습시키고 키가 165cm일 때의 예측값을 얻어보자.
키(열벡터)와 몸무게 데이터(행벡터)를 준비하고, 각각 numpy 배열로 변환해준다. 그리고 선형 회귀 모델을 초기화 시킨 후 학습을 시켜준다. 183cm라는 값을 예측모델에 입력데이터로써 넣어주면 그에 따른 몸무게의 값은 약 82kg로 나오는 것을 확인할 수 있었다. 정확도도 높게 나왔고, 그래프에서도 정답값과 예측값의 오차가 크지 않았다.
import numpy as np
from sklearn.linear_model import LinearRegression
from matplotlib import pyplot as plt
X = [[174],
[152],
[138],
[128],
[186],]
y = [71, 55, 46, 38, 88] # 행벡터
print(X)
print(y)
X = np.array(X)
y = np.array(y)
lr = LinearRegression()
lr.fit(X=X, y=y)
print(lr.score(X=X, y=y))
y_predict = lr.predict(np.array([[183]]))
print(y_predict) # 키에 따른 예측 몸무게
y_predicts = lr.predict(X)
plt.scatter(X, y_predicts, color='blue', marker='*') # 예측
plt.scatter(X, y, color='red', marker='o') # 정답
plt.show()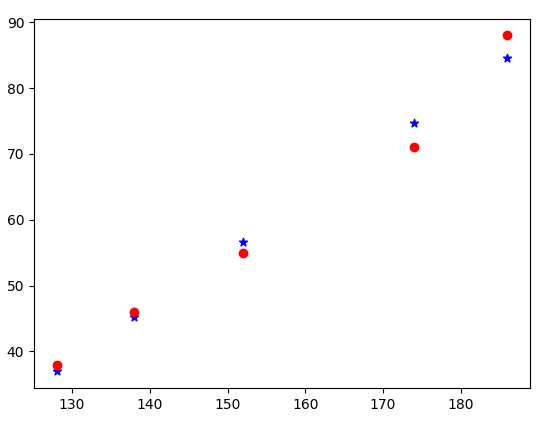

마무리
위에서 활용했던 데이터셋 중 가장 흥미로웠던 건 필기 데이터셋이었다. 개인적으로 쓰고있는 갤럭시탭에서 삼성노트를 사용할 때, 원이나 사각형 등 도형을 자주 그렸는데 이때 도형을 인식해서 의도한대로 도형을 깔끔하게 그려주는 기능이 있다. 이 기능도 아마 이 MNIST 필기체의 원리와 유사하지 않을까 생각이 들었는데, 자세한 원리는 기밀이라 찾아볼 수 없었던게 조금 아쉬웠다.
'ABC부트캠프 테크노트' 카테고리의 다른 글
| [22일차] ABC부트캠프 : 딥러닝1 (0) | 2024.08.02 |
|---|---|
| [21일차] ABC부트캠프 : ESG포럼 & 세미나3 (0) | 2024.08.02 |
| [19일차] ABC부트캠프 : 머신러닝1 (0) | 2024.07.30 |
| [18일차] ABC부트캠프 : 머신러닝 - 라이브러리 기초 (0) | 2024.07.29 |
| [17일차] ABC부트캠프 : 건양대 메디컬 캠퍼스 견학 (0) | 2024.07.26 |