들어가며
데이터의 집계와 처리에 대해서 자세히 다뤄보자. 데이터 집계를 통해 얻은 정보는 다양한 방법으로 데이터 처리에 사용된다. 대표적으로 데이터 집계를 통해 조건을 도출하여 데이터를 선택하는 방법이다.
데이터 집계와 데이터 처리
실습 데이터 프레임으로 `df_ins`를 활용했다.

지역별 비용의 평균집계를 구하고자 할 때에는 다음과 같이 작성이 가능하다.
# region을 기준으로 (4개) groupby히고 charges의 평균을 구함
df_agg = df_ins.groupby('region', as_index=False)['charges'].mean()
df_agg
# 비용의 평균이 높은 2개의 지역을 target으로 지정
targets = df_agg.nlargest(2, 'charges') # DataFrame타입
targets['region']
# target 지역에 속하는 데이터 구별을 위한 bool series 생성
cond = df_ins['region'].isin(targets['region'])
cond
# 조건에 의한 데이터(행)의 선택
df_ins.loc[cond]
피벗 테이블과 열지도의 활용
pandas의 `pivot_table()`을 활용하면 Excel의 피벗테이블과 동일한 표 형태의 집계가 가능하다. `aggfunc`는 어떤 집계값을 사용할 지 지정할 수 있다. 그룹함수를 이용하면 데이터프레임 형태는 다르지만 동일한 내용의 결과를 도출할 수 있다.
df_agg = df_ins.pivot_table(
columns='region', # 복수 가능
index='sex',
values='charges', # 복수 가능
aggfunc='mean'
)
display(df_agg)
# 그룹함수 (groupby) 를 통해서도 동일한 결과를 도출할 수 있음
df_grp = df_ins.groupby(['sex', 'region'], as_index=False)['charges'].mean()
df_grp
[실습] df_sp 활용
- `race/ethnicity`, `parental level of education` 별 (index, columns) `math score`(values)의 평균(aggfunc)를 피벗 테이블로 계산
- `1.`의 결과를 열지도로 시각화
import seaborn as sns
df_pvt = df_sp.pivot_table(
index='race/ethnicity',
columns='parental level of education',
values='math score',
aggfunc='mean'
)
sns.heatmap(df_pvt, annot=True, fmt='.2f')
# annot : 각 수치에 따른 위치에 값 표시
결과 데이터와 그래프의 저장
함수를 활용해서 분석 결과 데이터와 그래프를 저장할 수 있다. 다음은 대상 결과의 데이터를 피벗테이블을 이용해서 확인한 것이다.
# 대상 결과 데이터 확인
df_pt1 = df_ins.pivot_table(index='region', columns='smoker', values='charges', aggfunc='mean')
df_pt1
# to_csv()로 결과 데이터를 csv 형식으로 저장하기(한글 포함 시 인코딩방식 지정)
df_pt1.to_csv('./result/result.csv', index=True, encoding='CP949')
히트맵으로 대상 그래프를 확인한 것이다. 색은 `Blues`로, 색깔별로 수치를 표시하고 소숫점은 두자리까지 지정했다.
# 대상 그래프 확인
plot1 = sns.heatmap(df_pt1, cmap='Blues', annot=True, fmt='.2f')
plot1

# savefig()을 활용한 그래프 저장
plot1.figure.savefig('./result/plot1.jpg')
데이터 처리 심화
변수 수정, 추가 및 제거를 배우고, 변수의 형식변환, 결측값 처리 및 파생변수를 생성할 수 있다.
변수의 수정, 추가, 제거
pandas의 기본 기능과 메서드를 활용하여 변수를 추가하거나 수정, 업데이트하거나 제거가 가능하다. 변수를 선택하듯 `=`를 활용해서 변수를 추가하거나 업데이트 할 수 있다.
다음은 딕셔너리를 활용한 실습용 데이터프레임을 만든 것이다.
# 라이브러리 불러오기
import pandas as pd
# 예제 만들기 : 딕셔너리를 활용한 DataFrame 생성
df_own = pd.DataFrame({
'FIRST' : ['A', 'B', 'C', 'D', 'E'],
'SECOND': [7, 6, 5, 8, 9],
'THIRD' : pd.date_range('2023-01-01', periods=5, freq='W-SAT') # freq='W-SAT' : 매주 토요일, periods=주기 횟수
})
df_own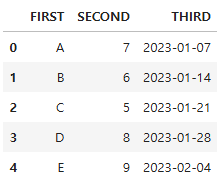
변수이름을 지정해서 원하는 값으로 추가, 수정이 가능하다.
# 변수이름을 활용한 변수선택
df_own['SECOND'] = 0
# 변수이름 추가
df_own['FOURTH'] = 0
df_own
# =을 활용한 업데이트
df_own['FOURTH'] = df_own['SECOND'] + 1
객체 메서드와 Series 메서드의 비교
날짜같은 경우 월, 일, 요일, 시간 등 다양한 요소를 추출해서 변수로 추가할 수 있다. 또한 Series에 대해서는 Series의 메서드만 활용이 가능하기 때문에 사용에 주의해야 한다.
df_own.loc[0, 'THIRD'].weekday() # 0인 인덱스, 'TRIRD' 변수에 해당하는 값의 요일 출력
## 0~6: 월~일
## 5: 토
## 하나의 값에 대해서는 메서드 활용가능
간편함수 `lambda`를 사용하여 apply에 전달할 수도 있다. 아래 `THIRD`날짜에 해당하는 요일의 값을 `Day`라는 변수의 값에 집어넣은 것이다. pandas의 `dt.weekday`를 활용하면 훨씬 손쉽게 파생변수 생성이 가능하다.
# 간편함수 lambda 사용하여 apply 전달
df_own['DAY'] = df_own['THIRD'].apply(lambda x: x.weekday())
df_own
# 함수로 기능을 선언하여 apply 전달
# def convertToDay(x):
# if x.weekday() == 5 :
# return '토요일'
# elif x.weekday() == 0:
# return '월요일'
# df_own['DAY'] = df_own['THIRD'].apply(convertToDay)
# df_own
조건을 활용한 값 변경, 생성
조건을 활용해 일부 관측치를 선택하듯이, 조건을 설정하고 변수를 추가하거나 업데이트가 가능하다.
# 조건을 활용한 일부 관측치 선택
cond = df_own['FIRST'].isin(['A','B'])
df_own.loc[cond]
A와 B에 해당하는 관측치의 `FOURTH` 값을 0으로 변경한 결과이다.
# 조건을 활용한 일부 관측치의 특정 변수 값 변경
cond = df_own['FIRST'].isin(['A','B'])
df_own.loc[cond, 'FOURTH']
df_own.loc[df_own['FIRST'].isin(['A','B']), 'FOURTH'] = 0
df_own

`OPTIONAL`변수의 값중 `FIRST`값이 A와 B인 곳에 9999값을 저장한다. 나머지 C와 D의 `OPTIONAL`값은 NaN으로 남는다.
# 일부 관측치만 값 생성
df_own.loc[df_own['FIRST'].isin(['A','B']), 'OPTIONAL'] = 9999
df_own
## NaN := 결측값(missing)
변수제거
`drop()`은 `index`와 `columns`를 활용하여 관측치와 변수를 제거할 수 있다. `axis`옵션에 따라 0이면 관측치를 제거하고 1이면 변수를 제거한다. `columns` 옵션을 명시해서 변수를 제거하는 것이 가장 명확하고 실수를 줄일 수 있다.
# drop()을 활용한 관측치/변수 제거
# axis = 0 : 관측치
# axis = 1 : 변수
df_own = df_own.drop('FOURTH', axis=1, inplace=True)# drop()을 활용한 관측치/변수 제거(columns 활용)
df_own.drop(columns=['THIRD'])# 원본 데이터의 업데이트
df_own = df_own.drop(columns=['FOURTH'])
df_own# 행의 삭제
df_own.drop([0, 3], axis=0)
변수 이름 변경
변수이름을 바꾸고 싶을 때는 `DataFrame`의 메서드 `rename()`을 활용할 수 있다. 이때 `columns`옵션을 활용하고 딕셔너리 형식으로 기존 변수이름과 새변수 이름을 콜론으로 연결한다.
# rename() 활용 변수 이름 바꾸기
df_own = df_own.rename(columns={'FIRST':'var1', 'SECOND':'var2'})
# 데이터프레임의 값을 직접 바꾸기
df_own.columns = ['a', 'b', 'c', 'd', 'e', 'f']
df_own
결측값 처리
결측값은 여러 이유로 발생한다.
- 애초에 값이 없는 경우
- 값이 있으나 사람 실수로 누락한 경우
- 센서, 통신망 등의 오류로 값이 들어오지 않은 경우
먼저 결측값 존재 여부를 확인하고, 대체할 지 그대로 둘지를 결정한다. 만약 대체한다면 어떤 값으로 채울지도 고민하여 지정한다.
# 예제 데이터 불러오기
df_na = pd.read_csv('./data/data_dupna.csv')
df_na
# NaN : 결측
다음과 같이 전체 데이터에서 결측값이 있는 관측치나 변수를 확인할 수 있다. `~cond`는 not연산이 들어갔으므로 info1 값중 결측치가 아닌 행을 의미한다.
# isnull 함수를 활용한 결측값 필터
cond = df_na['info1'].isnull()
# df_na[cond]
df_na[~cond]
# 여러개의 변수의 결측값 확인 및 필터
cond = df_na['info1'].isnull() | df_na['info3'].isnull()
# df_na[cond]
df_na[~cond]
`any()`함수를 활용하여 지정한 열의 결측값 여부를 확인할 수 있다.
# any 함수를 활용한 모든열의 결측값 필터
df_na.isnull()[['info1', 'info3']].any()
# cond = df_na.isnull().any(axis=1)
# df_na[~cond]# any 함수를 활용한 부분열의 결측값 필터
cond = df_na[['info1', 'info3']].isnull().any(axis=1)
df_na[~cond]
결측값 포함 관측치 제거
결측값이 있는 관측치에 대응하는 가장 간단한 방법은 결측치를 포함한 변수나 관측치를 제거하는 것이다.

결측값 대체
일반적으로 결측값을 그대로 두거나 다음과 같이 결측값을 적절한 값으로 대체하고 활용할 수 있다.
# 모든 결측값을 일괄 대체, 결측값을 0으로 대체
df_na.fillna(value=0)
지정한 변수마다 0, 'NA'라는 값을 따로 지정해주었다.
# 변수별 결측값 대체 지정
df_na.fillna(value={'info1':0, 'info2':'NA'})

`NaN`값 기준에서 위의 가장 가까운 결측이 아닌 값으로 대체한다. 아래쪽 값으로 대체할 경우에는 `bfill`을 지정한다.
# 가장 앞쪽의 결측이 아닌 값으로 대체
## 센서 등의 값 누락에 활용
df_na.fillna(method='ffill')
# 이후 값중 결측이 아닌 값으로 대체
## groupby()를 활용하여 id 등 범위 내 대체
df_na.groupby('id').fillna(method='bfill')
# 특정한 변수만 결측값 대체
## groupby()와 fillna()를 활용할 경우 그룹변수가 사라짐
## 특정 변수만 선택해서 결측값 대체하고 업데이트
df_na['info2'] = df_na.groupby('id')['info2'].fillna(method='ffill')
df_na

변수 형식 변환 및 파생변수 생성
`read_csv()`로 데이터를 불러오면 적당한 형식으로 지정되는데, 가끔 형식을 직접 바꿔야 할 상황이 있다. 상황에 따라 날짜에서 요일을 추출하듯이 기존 변수를 활용해서 새로운 변수를 추가해 분석에 활용해야하는 경우가 있을 수 있다.
변수 형식의 확인/변환
DataFrame에서는 다음과 같은 Series형식을 활용한다.
- `float` : 실수 (소수점을 포함한 숫자)
- `int` : 정수(integer)
- `datetime` : 날짜 시간
- `bool` : 불/불린(True 혹은 False)
- `category` : 범주형
- `object` : 문자형(string) 혹은 그 외
# children을 float으로 변환
df_ins['children'].astype('float').dtypes
# dtype('float64')# select_dtypes()의 활용
df_ins.select_dtypes('category')
# df_ins
[참고] 범주형 데이터 사용의 이점
범주형 데이터는 `category`의 순서를 부여하여 데이터 사이의 관계를 만들어 줄 수 있으며, 성능 및 그래프 그리기 등의 이점이 존재한다.
# 데이터 성능상의 이점 (적은 메모리 공간의 사용)
df_subway = pd.read_csv('./data/서울교통공사_역별일별승하차인원정보_20220731.csv')
df_subway
# df_subway.nunique()
# df_subway.info()
df_subway['호선'] = df_subway['호선'].astype('category')
df_subway['구분'] = df_subway['구분'].astype('category')
df_subway.info()# 점주형 데이터 간의 순서를 통한 정렬
df_products = pd.DataFrame({
'id': ['p1', 'p2', 'p3', 'p4', 'p5'],
'size': ['X-Large', 'Small', 'Large', 'X-Small', 'Medium']
})
df_products
df_products.sort_values('size')
# df_products['size'] = df_products['size'].astype('category')
# df_products['size'] = df_products['size'].cat.reorder_categories(["X-Small", "Small", "Medium", "Large", "X-Large"], ordered=True)
# df_products
# df_products.sort_values('size')
수치형 변수의 구간화
수치형 변수는 그대로 활용하기 보다는 구간화하는 경우가 많다. `cut()`이나 `qcut()`함수를 주로 활용한다.
- `cut()` : 등간격 혹은 주어진 구간 경계로 구간화
- `qcut()` : 등비율로 구간화
# 연령대 변수 생성
## //: 몫 계산
## %: 나머지 계산
df_ins['age'] // 10
df_ins['age_grp'] = (df_ins['age'] // 10).astype('category')
df_ins
`cut()`을 활용해서 등간격으로 구간화할 수 있고, `bins`옵션에 적절한 구간값을 직접 넣을 수도 있다.
# 등간격으로 구간화하기
pd.cut(df_ins['charges'], bins=10)
`charges_breaks`리스트에 구간값을 저장하여 `bins`옵션으로 넘겨주었다. 각 구간에 해당하는 값을 `labels`에 알파벳 A, B, C, D로 할당해줌으로써 하나의 시리즈를 도출해냈다. 0 < 5000 < 10000 < 20000 < 10000000 총 4가지 구간이 나오기 때문에 `'labels`에도 A,B,C,D 4개를 할당했다.
charges_breaks = [0, 5000, 10000, 20000, 100000000]
pd.cut(df_ins['charges'], bins=charges_breaks, right=True, labels=['A','B','C','D'])
0부터 9까지의 범위를 `labels`로 지정하고, 총 10등급으로 나누어 `charges_grp` 변수에 알맞은 등급을 할당해주었다. `cut()`은 절대적인 구간을 나누는데 사용된다.
# cut()을 활용한 10등급화
df_ins['charges_grp'] = pd.cut(df_ins['charges'], bins=10, labels=range(10))
df_ins
반대로 상대적인 구간을 따질 때에는 `qcut()`이 활용된다.
# qcut()을 활용한 등비율 구간화
df_ins['charges_grp2'] = pd.qcut(df_ins['charges'], q=10, labels=range(1, 11))
df_ins
마무리
데이터 집계 심화과정으로 들어오니 확실히 어려워졌다는 것을 몸소 느꼈다. 그리고 학교에서 다룬 기계학습 과정에서도 배우지 못한 데이터 처리 방법들이 생각보다 정말 많았다. 갑자기 어려워졌지만 예상을 못한 것도 아니니 그냥 묵묵히 해야겠다.
'ABC부트캠프 테크노트' 카테고리의 다른 글
| [11일차] ABC부트캠프 : 랭킹뉴스 크롤링 및 데이터 시각화 (0) | 2024.07.18 |
|---|---|
| [10일차] ABC부트캠프 : 데이터 집계 & 처리 미니프로젝트 (0) | 2024.07.17 |
| [8일차] ABC부트캠프 : 파이썬 프로그래밍 데이터 전처리 & 시각화 (2) | 2024.07.16 |
| [7일차] ABC부트캠프 : 파이썬 프로그래밍 데이터 전처리 기초 (0) | 2024.07.12 |
| [6일차] ABC부트캠프 : 파이썬 프로그래밍 미니프로젝트 (0) | 2024.07.11 |