
들어가며
데이터 분석 팀 프로젝트의 발표가 있는 날이다. 데이터 크롤링을 하는 과정에서 상당히 애를 먹었는데, 프로젝트를 완수하기까지 그 과정을 알아보자.
무신사어스 상품후기 데이터 크롤링
무신사어스 상품들의 후기를 수집할 것이기 때문에 후기가 많은 순으로 정렬한 후, 그 중 TOP10 상품들의 모든 일반후기들을 수집하는것이 목표이다. 먼저 메인페이지에 접속해서 html요소들 중 상품 정보가 담겨있는 class가 `info`인 `div`를 모두 찾는다.

def musinsa_collector(url):
df = pd.DataFrame() # 빈 데이터프레임 정의
driver.get(url)
time.sleep(STOP_TIME)
# 사람인 척 하는 동적 이벤트 주기 -> 스크롤 내리기(js 명령어)
driver.execute_script('window.scrollTo(0,800)')
time.sleep(STOP_TIME)
# 메인페이지 데이터 수집 시작(상품이름, 가격, 식별번호, 이미지)
html_source = driver.page_source
soup = BeautifulSoup(html_source, 'html.parser')
# 상품정보가 담긴 틀
div = soup.find_all('div', {'class':'info'})
그 다음 각 상품 별로 `이름`, `가격`, `식별번호`, `이미지` 를 가져올 것이다. 먼저 위의 `div` 태그 안에서 `이름`, `가격`, `식별번호`를 추출한다. 식별번호는 상품별 페이지 주소 맨 끝 부분에 포맷팅 해준 후, 그 페이지로 접속한다.

for index_div, div_el in enumerate(div[:10]):
# 상품 이름
pdt_a = div_el.find('a', {'class':'name ampl-catch-click'})
pdt_name = pdt_a.text
# 상품 가격
pdt_em = div_el.find('em', {'class':'sale grid'})
pdt_price = pdt_em.text[:-1].replace(',', '')
# 상품 식별 번호
pdt_link_a = div_el.find('a', {'class':'name ampl-catch-click'}).attrs['href']
pdt_link_num = pdt_link_a.split('/')[-1]
# 상품별 url
product_url = f'https://www.musinsa.com/app/goods/{pdt_link_num}'
driver.get(product_url) # 상품별 페이지 접속
time.sleep(STOP_TIME)
후기를 수집하는 과정이 가장 문제였다. 원래 목표는 스크롤을 살짝 내린 후에 `후기` 탭을 눌러서 자동으로 후기부분까지 스크롤을 내려주고, `일반`탭을 누른 후 1페이지, 2페이지.. 순차적으로 클릭해줌으로써 모든 일반 후기들을 수집하는 것이었다. 그러나 무신사 측에서 의도적으로 설계한 웹페이지 때문에 `후기`와 `일반`, 그리고 `1, 2, 3, 4`와 같은 다음 페이지 번호에 클릭이벤트를 발생시킬 수 없었다. 심지어 아래 이미지와 같이 첫번째 페이지 이외에 다음 페이지를 직접 클릭해서 넘어가도 그 페이지의 후기는 수집되지 않았다. 그나마 다행이었던 것은 후기 종류 탭인 `체험단`, `스타일`, `상품 사진`, `일반` 탭들은 코드로 클릭이벤트를 발생시킬 순 없지만 사람이 직접 클릭해주면 각 탭마다 첫 페이지의 후기(최대 10개)는 모두 수집할 수 있었다.



이미지는 여러 개의 이미지 중 접속하면 가장 먼저 보이는 것으로 추출했다.
# 댓글 확인하기 위해 하단 최대치에 근접하도록 스크롤
driver.execute_script('window.scrollTo(0,9000)')
time.sleep(STOP_TIME)
# 상품 페이지 소스 가져오기
html_rev = driver.page_source
soup_rev = BeautifulSoup(html_rev, 'html.parser')
# 댓글 박스(div) 가져오기
review = soup_rev.find_all('div', {'class':'review-list'})
# 상품 이미지 저장하기
if not os.path.exists('images'):
os.makedirs('images')
img_tag = driver.find_element(By.CSS_SELECTOR, 'img[src].sc-1jl6n79-4.AqRjD')
img_src = img_tag.get_attribute('src')
img_name = f"{index_div+1}_{pdt_link_num}.jpg" # 순서와 상품 식별 번호를 포함한 파일명
img_path = os.path.join('images', img_name)
response = requests.get(img_src)
with open(img_path, 'wb') as file:
file.write(response.content)
위에서 추출한 `div`로 구성된 댓글박스 중에서 `별점`과 `글 내용`을 수집했다. 별점은 css의 `width`옵션을 이용해서 100%를 5로 나눈 값으로 별의 개수를 표현한 것으로 확인됐다.
| ★ ☆ ☆ ☆ ☆ | `width=20%` |
| ★ ★ ☆ ☆ ☆ | `width=40%` |
| ★ ★ ★ ☆ ☆ | `width=60%` |
| ★ ★ ★ ★ ☆ | `width=80%` |
| ★ ★ ★ ★ ★ | `width=100%` |
댓글의 내용은 `<br>`, 연속된 공백문자 등 불필요한 문자를 제거해줬다. 결과적으로 데이터프레임에 넣고자 하는 값들은 `상품명`, `가격`, `별점`, `댓글`이므로 지금까지 추출한 값들을 하나의 행 형태로 쌓아나가는 흐름을 구성했다.

# 댓글 정보 수집
for rev in review:
star = rev.find('span', {'class':'review-list__rating__active'}).attrs['style'].split()[1].replace('%','')
comment = rev.find('div', {'class':'review-contents__text'})
comment = str(comment).replace('<br/>', ' ')
cleaner = re.compile('<.*?>')
clean_comment = re.sub(cleaner, '', comment)
clean_comment = re.sub('\s+', ' ', clean_comment)
tmp_df = pd.DataFrame({'상품명':[pdt_name],
'가격':[pdt_price],
'별점':[star],
'댓글':[clean_comment]})
df = pd.concat([df, tmp_df], axis=0)
df.to_csv('./무신사_어스_TOP10_추출파일.csv', index=False, encoding='utf-8-sig')
print('무신사 어스 상품 TOP10 수집 완료')
driver.close()
# 무신사 어스 후기순 랭킹 페이지
url = 'https://www.musinsa.com/spc/earth/goods?includeSoldOut=false&sortCode=REVIEW&listViewType=3GridView&page=1&size=120&useCustomPrice=false'
musinsa_collector(url)
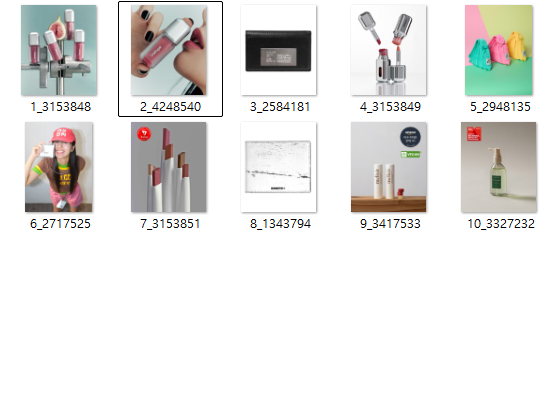
csv파일과 이미지가 다음과 같이 잘 나온 것을 확인할 수 있다.

무신사 어스 상품후기 데이터 시각화
이제 수집한 데이터를 바탕으로 시각화를 시도해볼 차례이다.

모든 후기의 단어 빈도수

환경과 관련된 내용이 담긴 후기의 단어 빈도수

분석 결론
소비자들은 대체적으로 ESG 제품을 구매할 때 ESG에 대한 큰 고려를 하지 않는 것으로 보였다. 환경도 물론 중요하지만 1차적으로 먼저 고려되는 것은 역시 제품의 품질과 사용성 부분이었다. 기업에서 환경을 고려한 제품이 다른 제품과 어떤 차별점을 가지는지, 또 환경적인 부분에서 어떤 긍정적인 효과를 가져올 수있는지 시각적으로 명확하게 제시해주면 소비자 입장에서도 더 좋지 않을까 싶다.
마무리
짧은시간동안 각자 역할을 충실하게 해낸 조원들에게 정말 고생많았다는 이야기를 해주고 싶다. 그리고 크롤링 부분에서 다소 어려움이 있었는데, 아무래도 주제 선정에서 크롤링 가능 여부를 확인하기 위해 웹사이트 체크를 했었더라면 더 좋았을 것 같다. 참신하고 연구할 가치가 있는 주제를 선정하는 것도 좋지만, 그 전에 기술적으로 구현이 가능한지 따져보는 것이 정말 중요함을 몸소 느꼈던 프로젝트였다.
'ABC부트캠프 테크노트' 카테고리의 다른 글
| [18일차] ABC부트캠프 : 머신러닝 - 라이브러리 기초 (0) | 2024.07.29 |
|---|---|
| [17일차] ABC부트캠프 : 건양대 메디컬 캠퍼스 견학 (0) | 2024.07.26 |
| [15일차] ABC부트캠프 : 구글 이미지 크롤링 및 데이터 분석 팀 프로젝트(1/2) (0) | 2024.07.24 |
| [14일차] ABC부트캠프 : 음악 정보 수집 및 시각화 (0) | 2024.07.23 |
| [13일차] ABC부트캠프 : 유튜브 댓글 수집 및 시각화 (6) | 2024.07.22 |