들어가며
유튜브에 이어서 이번엔 멜론 차트의 음악 정보를 수집해보는 시간이다. 음악으로 어떤 분석을 할 수 있을지 직접 실습을 통해 배워나가보자.
멜론 2020년 TOP30 크롤링
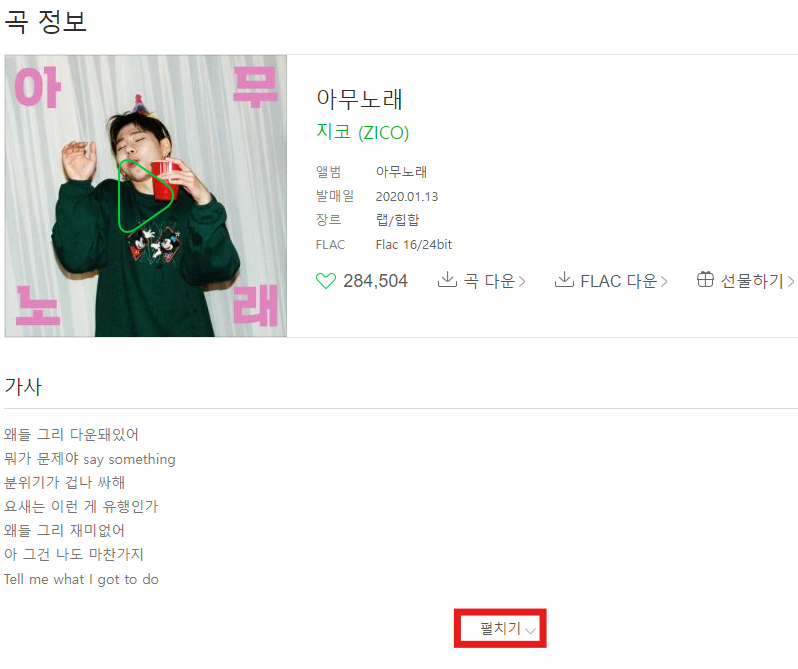
우리는 2020년도의 순위차트에서 30개만 수집을 할 것이다. 너무 많이하면 사이트 접속이 안될 수도 있기 때문에 개수는 30개로 잡았다. 또한 각 노래마다 정보를 담고 있는 사이트를 가지고 있는데 이 사이트에서 가사를 모두 수집하기 위해서는 펼치기 버튼을 클릭해줘야한다. 즉, 유튜브에서 댓글을 스크롤을 해줘야하는 것처럼 동적 크롤링이 필요하다.

1. 라이브러리 불러오기 및 크롬브라우저 옵션 세팅
from selenium import webdriver # 웹애플리케이션 테스트 자동화 도구
# Selenium을 사용하여 크롬브라우저를 자동화할 때 필요한 크롬 드라이버를 관리하는 데 사용
from webdriver_manager.chrome import ChromeDriverManager
# 크롬브라우저 서비스를 제어하기 위해 필요한 클래스
from selenium.webdriver.chrome.service import Service as ChromeService
# 웹 페이지에서 특정 요소를 식별하기 위한 메서드 제공
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup # HTML 및 XML 문서를 파싱하는 데 사용
import time # 시간 지연에 사용
import pandas as pd # 데이터프레임 활용
import re # 정규표현식 활용
from pytz import timezone # 위치에 따른 시간 기록
import datetime # 현재시간 가져오기
import warnings # 경고메시지를 발행하는 방법 제공
warnings.filterwarnings('ignore') # 콘솔에 출력할 모든 경고를 '무시'options = webdriver.ChromeOptions() # 크롬브라우저의 옵션을 설정하기 위한 객체 생성
options.add_argument('--no-sandbox') # 보안 기능인 샌드박스 비활성화
options.add_argument('--disable-dev-shm-usage') # dev/shm 디렉토리 사용 안함
# 크롬 드라이버 서비스 설정 및 설치
service = ChromeService(executable_path=ChromeDriverManager().install())
# WebDriver 객체 생성 및 Chrome 브라우저 실행
driver = webdriver.Chrome(service=service, options=options)
2. 음악 정보를 수집하는 함수 기능 구현
`melon_collector`라는 이름으로 음악 정보를 수집하는 함수를 작성한다. 블록을 나눠가며 어떤 기능을 구현했는지 알아보자. 먼저 웹페이지에 접속하고 렌더링을 3초 기다린 후 접속차단을 방지하기 위한 동적 이벤트(스크롤 내리기)를 구현했다.
def melon_collector(url, start):
print(str(start) + '년도 멜론 TOP30 수집 시작...')
driver.get(url) # 해당 웹페이지 접속
time.sleep(3)
# 사람인 척 하기 동적 이벤트 주기 -> 스크롤 내리기(js 명령어)
driver.execute_script('window.scrollTo(0,800)')
time.sleep(3)
데이터 수집을 위해 html태그를 이용하여 노래 TOP 30개의 제목과 가수이름을 수집한다. 또한 곡 정보 페이지에 들어가기 위해 노래마다 ID값을 저장하기 위한 준비를 해준다.
# 데이터 수집 시작
html_source = driver.page_source # 웹페이지 소스 가져오기
soup = BeautifulSoup(html_source, 'html.parser') # html 파싱
# 노래 제목 30개 추출
# 클래스 이름에 ellipsis와 rank01을 포함하는 요소 모두 찾기
titles = driver.find_elements(By.CSS_SELECTOR, '.ellipsis.rank01')
title_list = [title.text for title in titles][:30]
# 가수 이름 30개 추출
# 클래스 이름에 ellipsis와 rank02를 포함하는 요소 모두 찾기
singers = driver.find_elements(By.CSS_SELECTOR, '.ellipsis.rank02')
singer_list = [singer.text for singer in singers][:30]
# 가사 수집을 위한 songId 추출 준비
song_info = soup.find_all('div', {'class':'ellipsis rank01'})
# 노래의 ID값을 저장할 리스트 선언
songid_list = []
곡 ID값을 모두 추출하기 위해 `href`에 할당된 자바스크립트 코드에서 정규식을 활용하여 ID값만을 추출할 것이다.
<a href="javascript:melon.play.playSong('19070207','32313543');">
`re`를 사용하여 숫자가 아닌 값들을 제거해주면 `19070207, 32313543`가 되는데 여기서 `,`을 기준으로 `split()`해주면 인덱스가 1인 값이 우리가 찾고자 하는 곡의 ID값이 된다. 에러발생 시에는 아무문자도 추가하지 않고 `pass`하여 예외처리를 해준다.
# songid 추출
for sid in song_info[:30]:
try: # attrs 생략가능 [], [1]:'32313543'
info = re.sub('[^0-9]', '', sid.find('a')['href'].split(',')[1])
songid_list.append(info)
except:
songid_list.append('')
print('song id not found...')
pass
# 가사 수집
song_cnt = 0 # 개수를 세는 변수
lyrics_list = [] # 가사 저장 리스트
이제 추출된 곡ID개수 만큼 반복해서 정보를 수집해준다. ID값이 존재할 경우에는 해당하는 곡 정보 페이지에 접속해서 3초간격으로 가사 펼치기 버튼을 클릭하고 가사를 수집하는 과정을 반복한다. 가사가 담긴 태그의 class이름은 `lyric`이다.
for song_id in songid_list:
if song_id:
print(str(song_cnt+1) + ' : ' + title_list[song_cnt] + ' 노래 가사 수집 중...')
song_cnt += 1 # 개수 세기
# 곡 정보 페이지 이동
song_url = f'https://www.melon.com/song/detail.htm?songId={song_id}'
driver.get(song_url)
time.sleep(3)
# 가사 펼치기 버튼 클릭 class="button_more arrow_d"
driver.find_element(By.CSS_SELECTOR, '.button_more.arrow_d').click()
time.sleep(3)
# 가사 수집하기
html_source = driver.page_source
song_soup = BeautifulSoup(html_source, 'html.parser')
lyric = song_soup.select_one('.lyric')
곡정보에 가사가 존재하면, 가사부분을 정제하는 과정을 거친다. html 줄바꿈 문자가 실제로는 `<br/>`로 존재하기 때문에 한 줄로 이어붙이기 위해서 `' '`공백문자로 대체해준다. 그리고 html태그를 찾는 정규식 `<.*?>`으로 태그를 찾고 `lyric`에 해당하는 `cleaner`(태그 뭉치)를 지워줬다. 불필요한 스페이스 문자를 정리해주기 위해서 `\s`가 두개 이상`\s+`일 경우를 하나의 공백으로 대체했다. 이렇게 깔끔하게 정리된 가사는 `lyric_list`에 저장된다.
곡ID가 존재하지 않거나, 곡ID는 있지만 가사가 존재하지 않는 경우는 모두 아무것도 추가하지 않는 액션을 취한다.
if lyric:
# lyric.text 해서 텍스트를 추출 (tag를 지우고 텍스트만 반환)
# <br> 태그를 삭제하면서, 띄어쓰기가 안되는 문제 발생
# 내가 직접 텍스트를 추출 (실제로는 '<br/>')
lyric = str(lyric).replace('<br/>', ' ')
# html 태그 찾는 정규식 : <.*?>
cleaner = re.compile('<.*?>')
# html 태그 지우기
clean_lyric = re.sub(cleaner, '', lyric)
# \s : 스페이스, +: 2개이상일 때만
clean_lyric = re.sub('\s+', ' ', clean_lyric) # 공백 지우기
lyrics_list.append(clean_lyric)
else: # 가사가 없는 경우
lyrics_list.append('') # 아무것도 추가X
else: # 곡 ID가 없는 경우
lyrics_list.append('') # 아무것도 추가X
크롤링한 날짜를 저장하고 추출한 데이터들을 데이터프레임으로 저장한 후 csv파일로 내보낸다. 수집이 완료되면 브라우저는 자동으로 종료한다.
# 크롤링한 날짜를 형식에 맞게 저장
crawling_date = datetime.datetime.now(timezone('Asia/Seoul')).strftime('%Y%m%d')
# 데이터 프레임 저장
df = pd.DataFrame({'노래제목':title_list,
'가수':singer_list,
'가사':lyrics_list})
df.to_csv(f'멜론 {start}년 TOP30_{crawling_date}.csv', index=False, encoding='utf-8-sig')
print(f'멜론차트 {start}년 TOP30 수집 완료')
driver.close()
3. 데이터 수집 연도, URL주소 설정 및 함수 실행
2020년도 차트의 곡을 수집할거기 때문에 `start`변수에 2020을 할당하고, URL은 끝부분에 start를 붙여주기 때문에 연도를 지워줬다. 코드를 실행해보면 다음과 같이 제목과 가수, 가사가 모두 잘 수집된 것을 확인할 수 있다.
# 데이터 수집할 연도 설정
start = 2020
# 데이터 수집할 URL 주소 설정
url = ('https://www.melon.com/chart/age/index.htm?chartType=YE&chartGenre=KPOP&chartDate=')
new_url = url + str(start)
# 함수 실행
melon_collector(new_url, start)
멜론 TOP30 노래 정보 시각화
이제 수집된 음악 정보를 바탕으로 시각화를 진행해보자.
1. 패키지 설치 및 임포트
늘 그랬듯이 필요한 패키지를 설치하고 라이브러리를 불러온다.
!pip install koreanize-matplotlib # matplotlib에서 한글 지원import pandas as pd # 데이터프레임 다루기 위함
from collections import Counter # 수 카운트
import re # 정규표현식 활용
from wordcloud import WordCloud # 워드클라우드 활용
import plotly.express as px # 그래프 그리기1
import matplotlib.pyplot as plt # 그래프 그리기2
import koreanize_matplotlib # matplotlib에서 한글 지원
2. 데이터 전처리
수집한 데이터가 저장된 csv파일을 데이터프레임으로 변환한다.
# 1) 데이터 프레임 불러오기
df = pd.read_csv('/content/drive/MyDrive/ABC부트캠프/멜론 2020년 TOP30_20240723.csv')
df.head()

수집된 가사에서 불필요한 단어들을 모은 리스트를 생성한다. 생각나는 것들만 초기화 한 후 나중에 시각화 하고나서 불용어들을 추가해나갈 수 있다. `remove_stopwords`함수는 매개변수로 받은 리스트에서 불용어가 제외된 단어들을 모아 리스트로 반환한다.
# 불용어 리스트
stopwords = ['은', '는', '이', '가', '으로', '에', '어', '그', 'a', 'the', 'an', 'i', '것', '수', '한', 's']
def remove_stopwords(words):
return [word for word in words if word not in stopwords]
가사들을 공백을 기준으로 모두 합치고, 이 합친 결과가 담긴 `all_lyrics`에서 단어들을 모두 추출한다. 그리고 위에서 정의한 `remove_stopwords`함수에 추출한 단어가 모인 `words`를 인자로 넣어서 불용어를 처리해준다.
# 가사에 단어 추출
# 2) 가사 컬럼만 보고 하나의 문자열로 합치기
all_lyrics = ' '.join(df['가사'])
# 3) 단어 추출
# 가사 뭉치에서 단어를 추출하고, 단어의 빈도를 계산
# r은 raw데이터, 코드 그대로 출력
# \b는 word boundery 단어의 시작과 끝에 있는 문자로 매칭
# \w는 word의 약자로 알파벳, 숫자, _ 문자를 찾기
words = re.findall(r'\b\w+\b', all_lyrics.lower())
# 4) 불용어 처리
words = remove_stopwords(words)
3. 단어 빈도표 만들기
빈도를 시각화하기 위해서 상위 20개 단어와 그 빈도수를 각 변수에 저장해준다.
# words의 빈도를 계산하고 딕셔너리 형태로 반환
word_freq = Counter(words)
# 상위 20개 단어 저장
top_words = [word for word, freq in word_freq.most_common(20)]
# 상위 20개 단어의 빈도수 저장
top_freqs = [freq for word, freq in word_freq.most_common(20)]
4. 시각화
막대 그래프
가사 속 단어 빈도수 상위 20개의 단어를 막대 그래프로 확인한 결과이다. `da`라는 단어가 압도적으로 많이 집계됐고, 전체적으로 가사에 영어단어가 많이 쓰였다는 것을 알 수 있다.
plt.figure(figsize=(10, 6)) # 10,6 사이즈의 도면 생성
plt.bar(top_words, top_freqs) # x=단어, y=빈도수
plt.xlabel('단어')
plt.ylabel('빈도수')
plt.title('가사 단어 빈도수 TOP20')
plt.xticks(rotation=45) # 가독성위한 x축 단어 기울이기
plt.show()
워드 클라우드
가장먼저 영어단어가 눈에띄는 워드클라우드의 모습이다.
# 워드 클라우드 시각화
font_path='/content/drive/MyDrive/ABC부트캠프/BMDOHYEON_ttf.ttf'
# 이미 집계된 단어의 빈도수를 활용(dic)
wc = WordCloud(width=800, height=400, font_path=font_path).generate_from_frequencies(word_freq)
plt.figure(figsize=(10, 6))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
추출한 30개 가사의 모든 단어 빈도 수를 집계한 막대그래프
# 데이터프레임에서 컬럼명이 0이면 이름 미지정 상태
word_df = pd.DataFrame.from_dict(word_freq, orient='index').reset_index()
word_df.columns = ['word', 'count'] # 컬럼명 지정
word_df = word_df.sort_values('count', ascending=False) # 빈도 수 내림차순 정렬
마무리
유튜브 댓글 구조와 비교해서 멜론 음악 정보의 구조는 자바스크립트 코드까지 얽혀있어서 조금 더 복잡하게 느껴졌다. 또한 `<br>`이 실제로는 `<br/>`로 인식한다는 것을 처음알았는데, 코드가 눈에 보이는 그대로가 아니라는 점에 조금 벙쪘던 것 같다. 여러 분야로 시각화를 진행해보니 사람마다 분석 방향이나 보는 관점이 다 달라서 그 점이 무척 흥미로웠다.
'ABC부트캠프 테크노트' 카테고리의 다른 글
| [16일차] ABC부트캠프 : 데이터 분석 팀 프로젝트(2/2) (0) | 2024.07.25 |
|---|---|
| [15일차] ABC부트캠프 : 구글 이미지 크롤링 및 데이터 분석 팀 프로젝트(1/2) (0) | 2024.07.24 |
| [13일차] ABC부트캠프 : 유튜브 댓글 수집 및 시각화 (6) | 2024.07.22 |
| [12일차] ABC부트캠프 : ESG포럼 & 세미나2 (0) | 2024.07.19 |
| [11일차] ABC부트캠프 : 랭킹뉴스 크롤링 및 데이터 시각화 (0) | 2024.07.18 |